Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
(PDF) LAVA: Language Audio Vision Alignment for Contrastive Video Pre ...
Character Identifying Video Language Alignment Network for Weakly ...
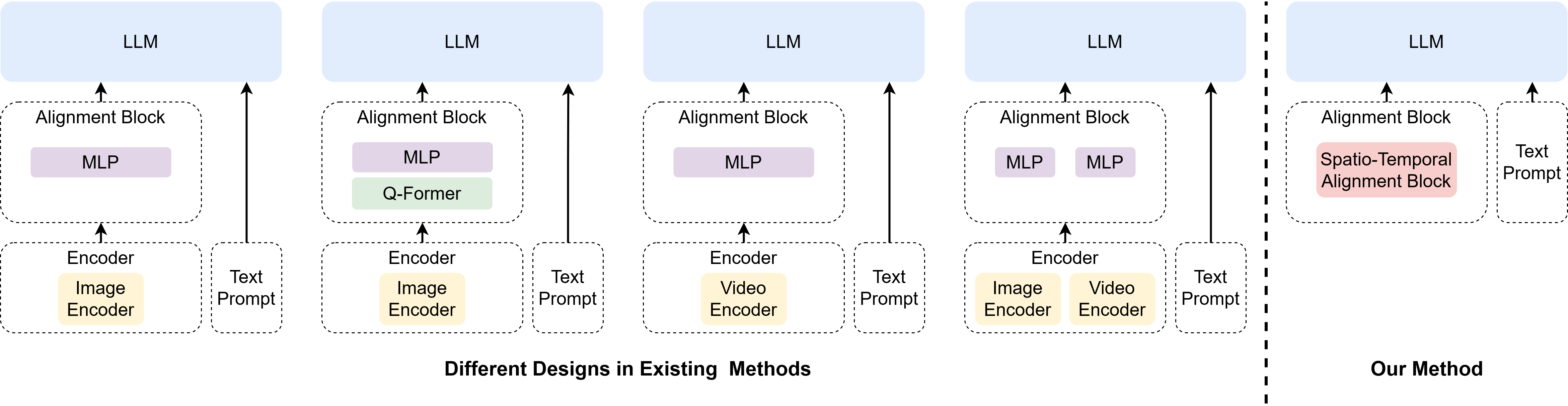
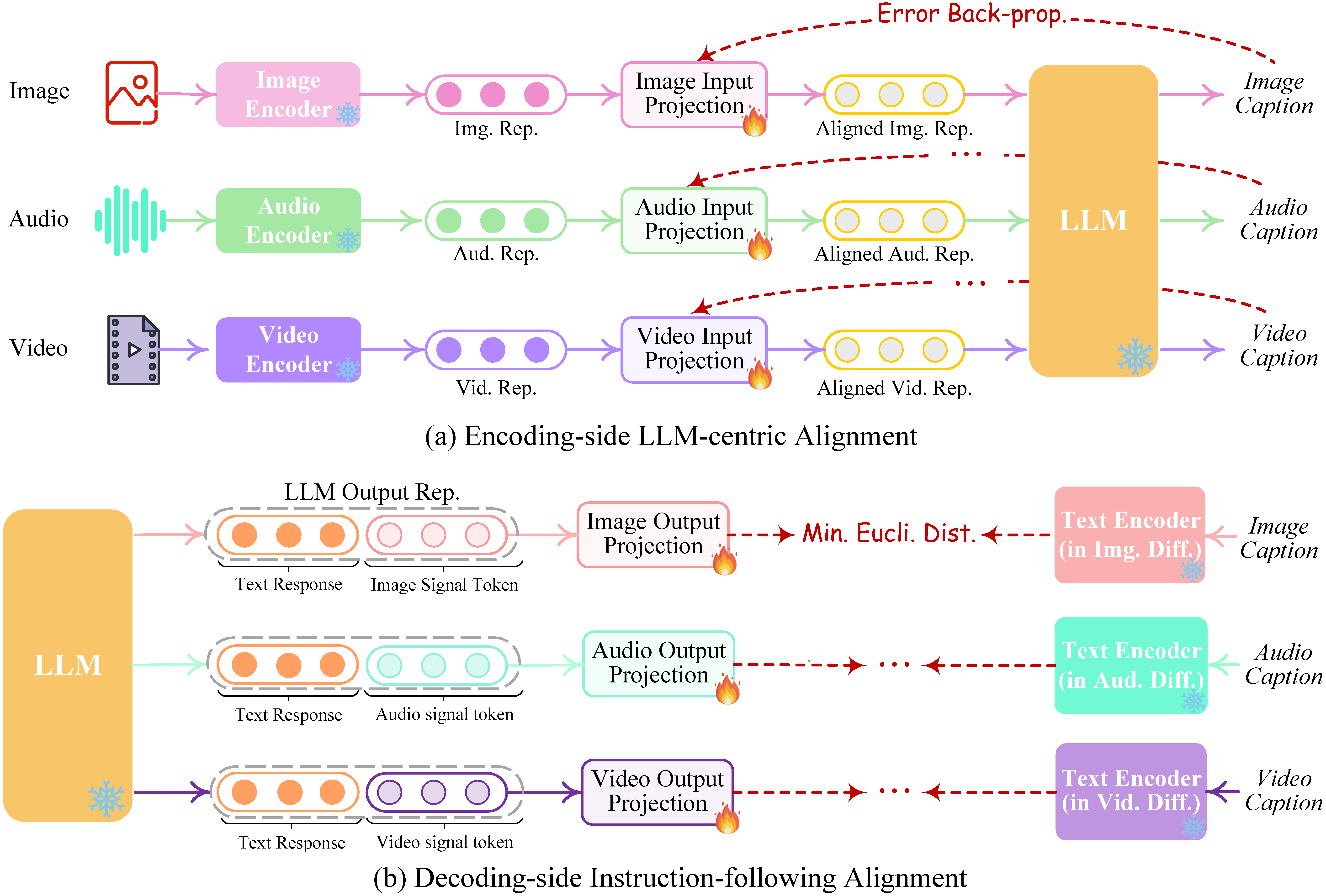
X-VILA: Cross-Modality Alignment for Large Language Model | AI Research ...
Video-Panda: Parameter-efficient Alignment for Encoder-free Video ...
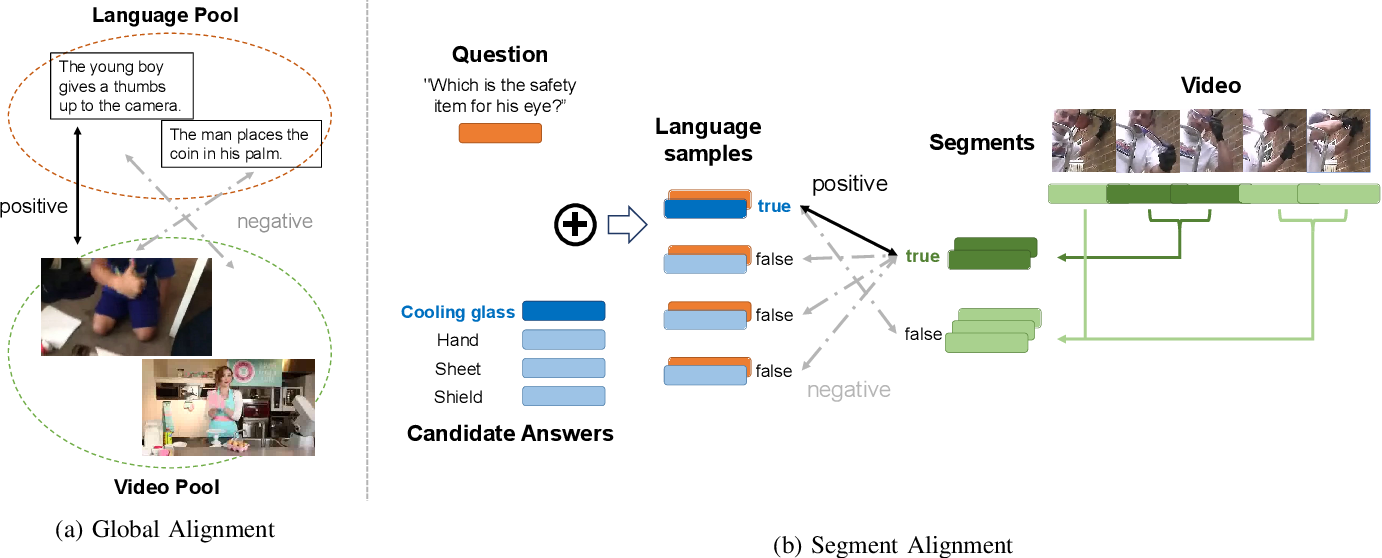
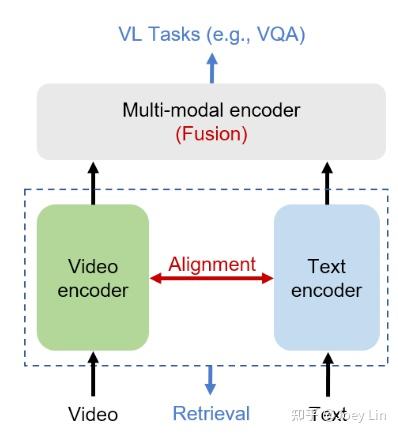
ViLA: Efficient Video-Language Alignment for Video Question Answering
Human Alignment of Large Language Models throughOnline Preference ...
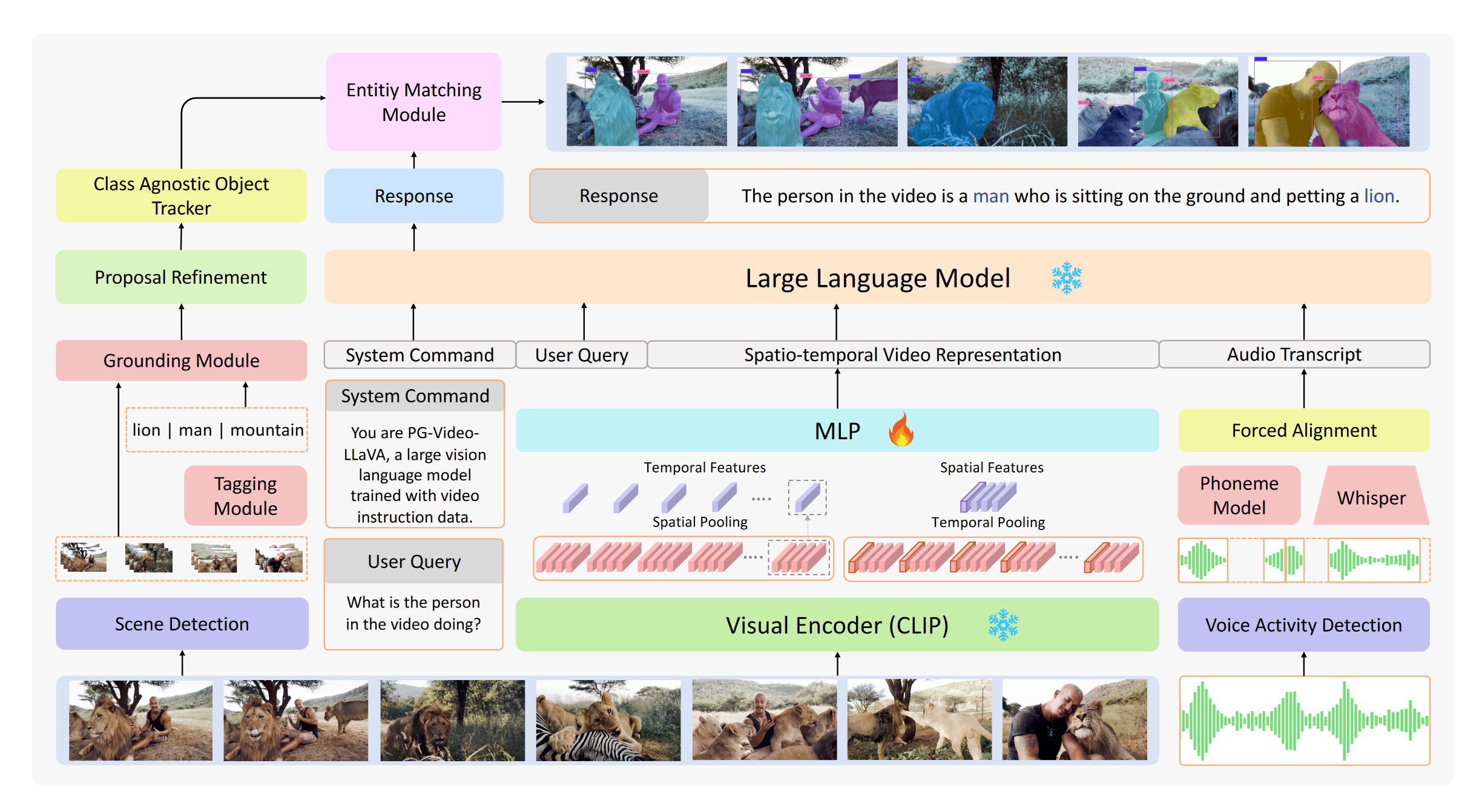
[논문 리뷰] Self-alignment of Large Video Language Models with Refined ...
VL-Few: Vision Language Alignment for Multimodal Few-Shot Meta Learning
PPT - Video Alignment PowerPoint Presentation, free download - ID:9555209
Language Alignment via Nash-learning and Adaptive feedback | AI ...
[论文评述] Deep Understanding of Sign Language for Sign to Subtitle Alignment
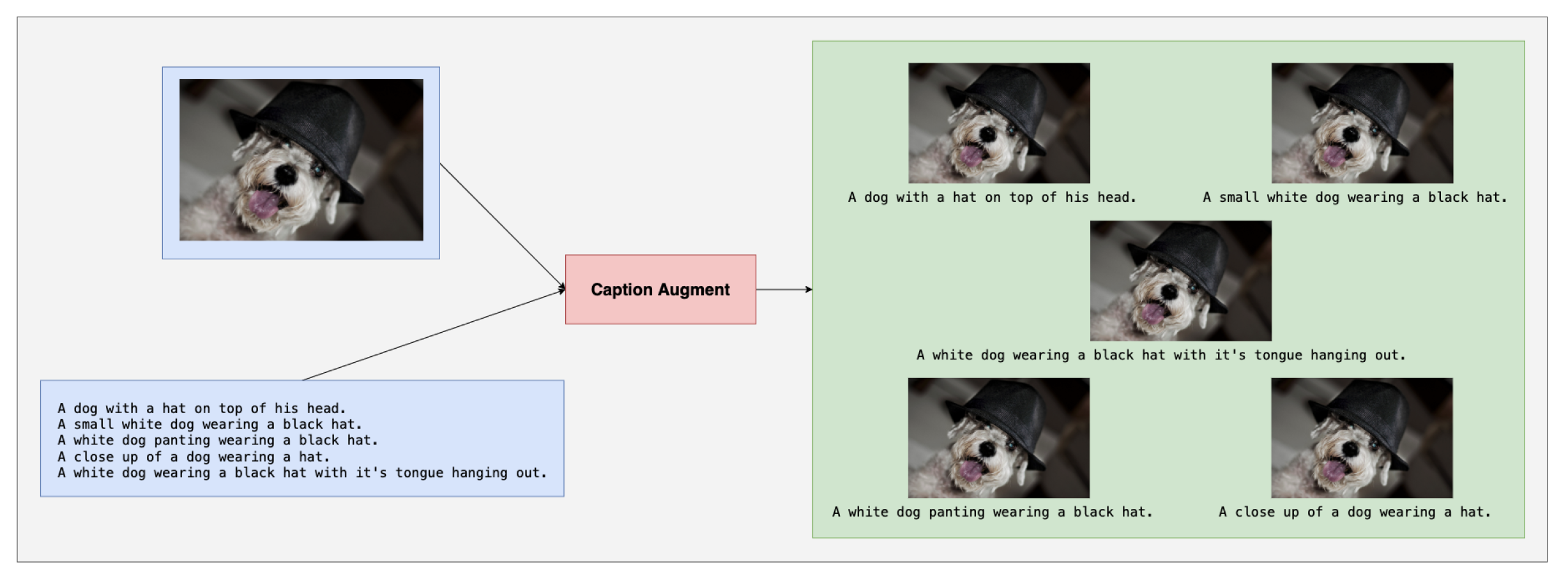
(PDF) Video Captioning based on Augmented Semantic Alignment
Unit 2.4 Alignment of the language and literacy domains - YouTube
Adding Alignment Control to Language Models | AI Research Paper Details
English language option alignment chart : r/AlignmentCharts
Choosing the Right Language Model Alignment Strategy | Faezeh ...
Contrastive Alignment of Vision to Language Through Parameter-Efficient ...
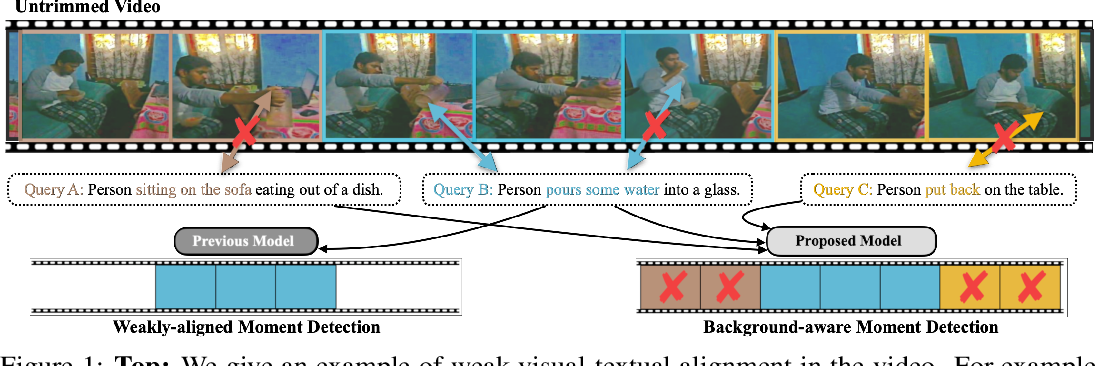
Overcoming Weak Visual-Textual Alignment for Video Moment Retrieval ...
Free Video: Safety Alignment in Large Language Models - Making Safety ...
Efficient Alignment of Large Language Models Using Token-Level Reward ...
Understanding Alignment Faking in Large Language Models | Galaxy.ai
How to Adjust Video Alignment on iPhone and iPad (2020) | Beebom
(PDF) VL-Few: Vision Language Alignment for Multimodal Few-Shot Meta ...
CM-Align: Consistency-based Multilingual Alignment for Large Language ...
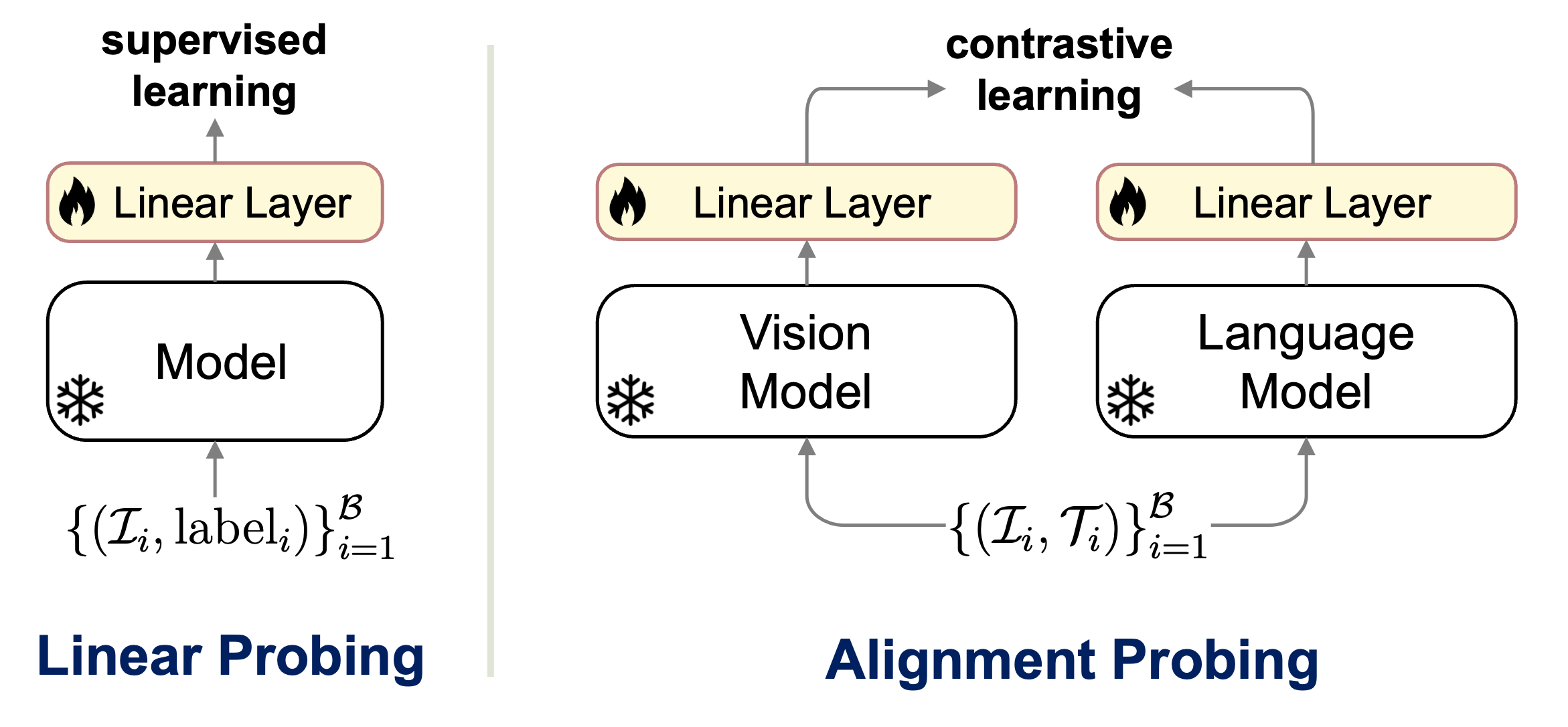
(PDF) Better Language Models Exhibit Higher Visual Alignment
Visual Representation Alignment for Multimodal Large Language Models ...
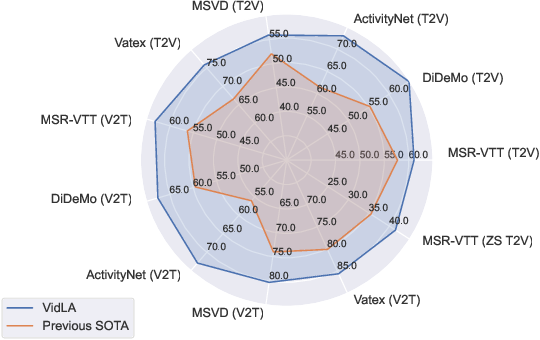
CVPR Poster VidLA: Video-Language Alignment at Scale
Video-Language Alignment via Spatio-Temporal Graph Transformer - 智源社区论文
Figure 4 from A Multi -level Alignment Training Scheme for Video-and ...
Figure 1 from Learning Video-Text Aligned Representations for Video ...
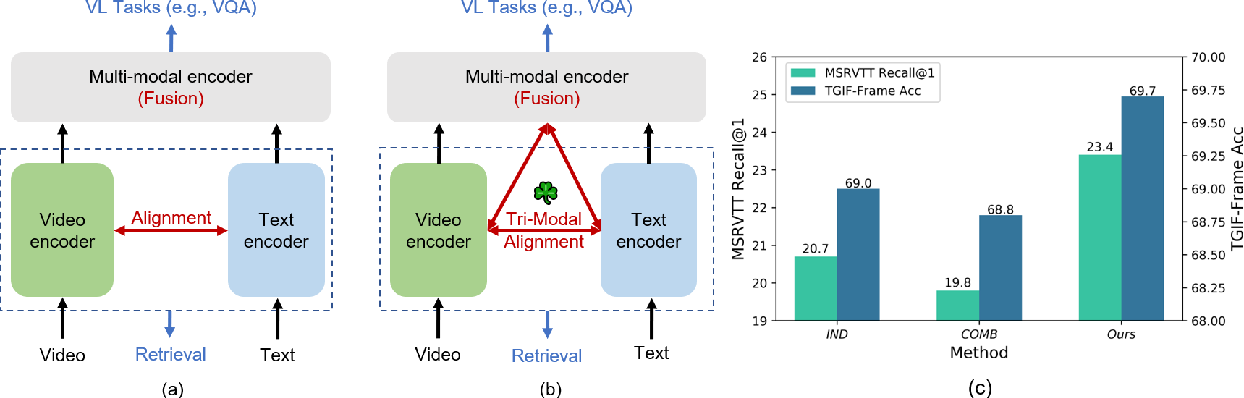
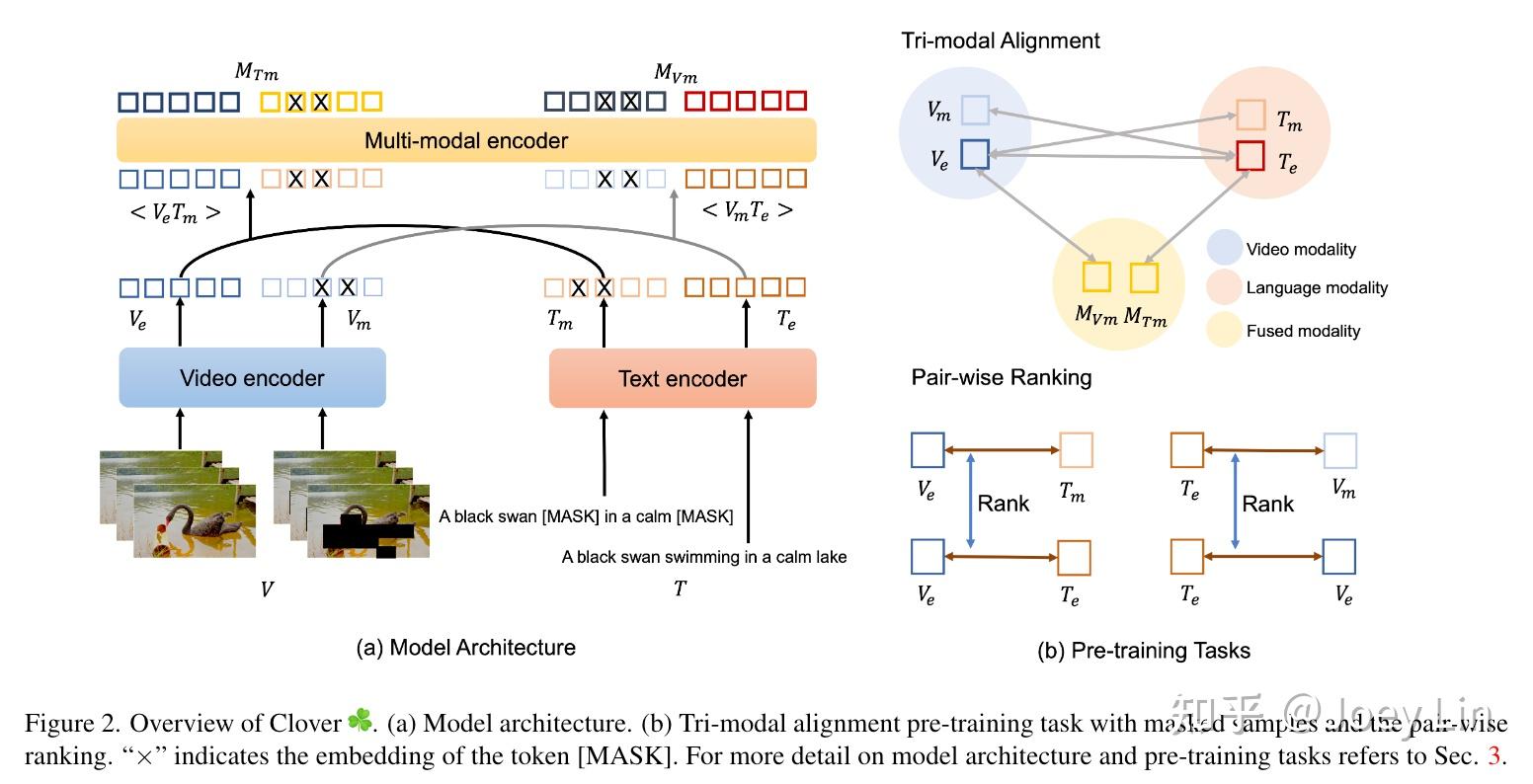
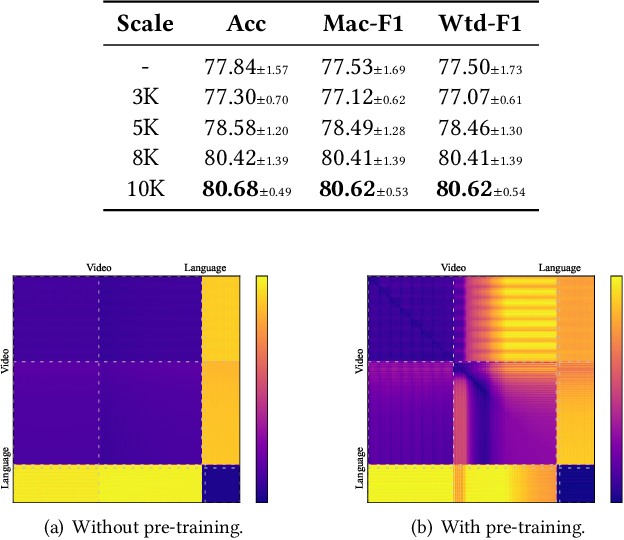
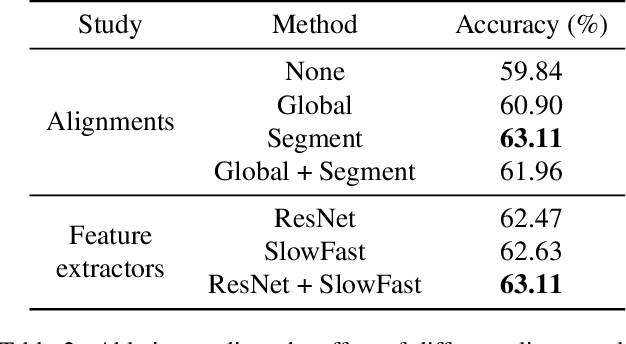
【CVPR2023】Clover : Towards A Unified Video-Language Alignment and ...
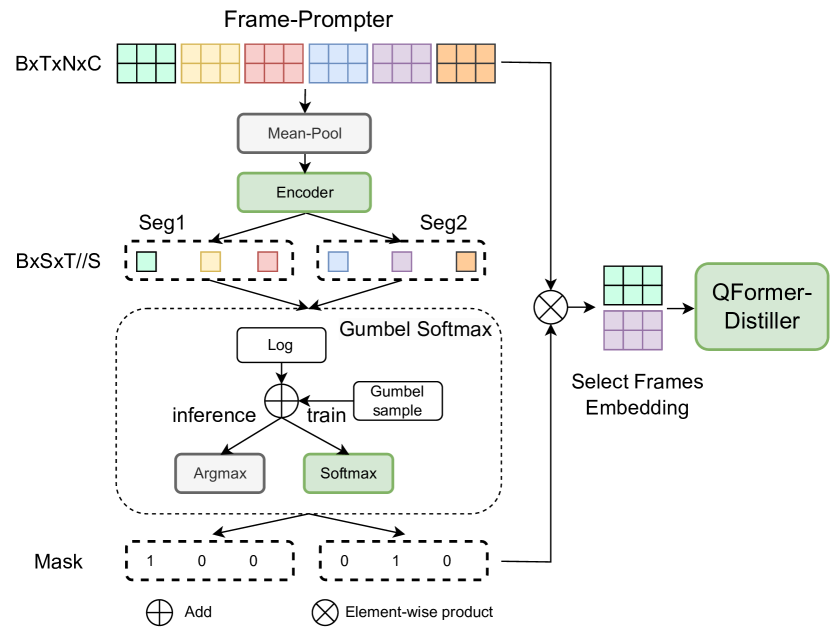
Paper page - VLAP: Efficient Video-Language Alignment via Frame ...
Paper page - VideoCon: Robust Video-Language Alignment via Contrast ...
Temporal Video-Language Alignment Network for Reward Shaping in ...
How To Localize Your Video Content For Different Audiences Using An AI ...
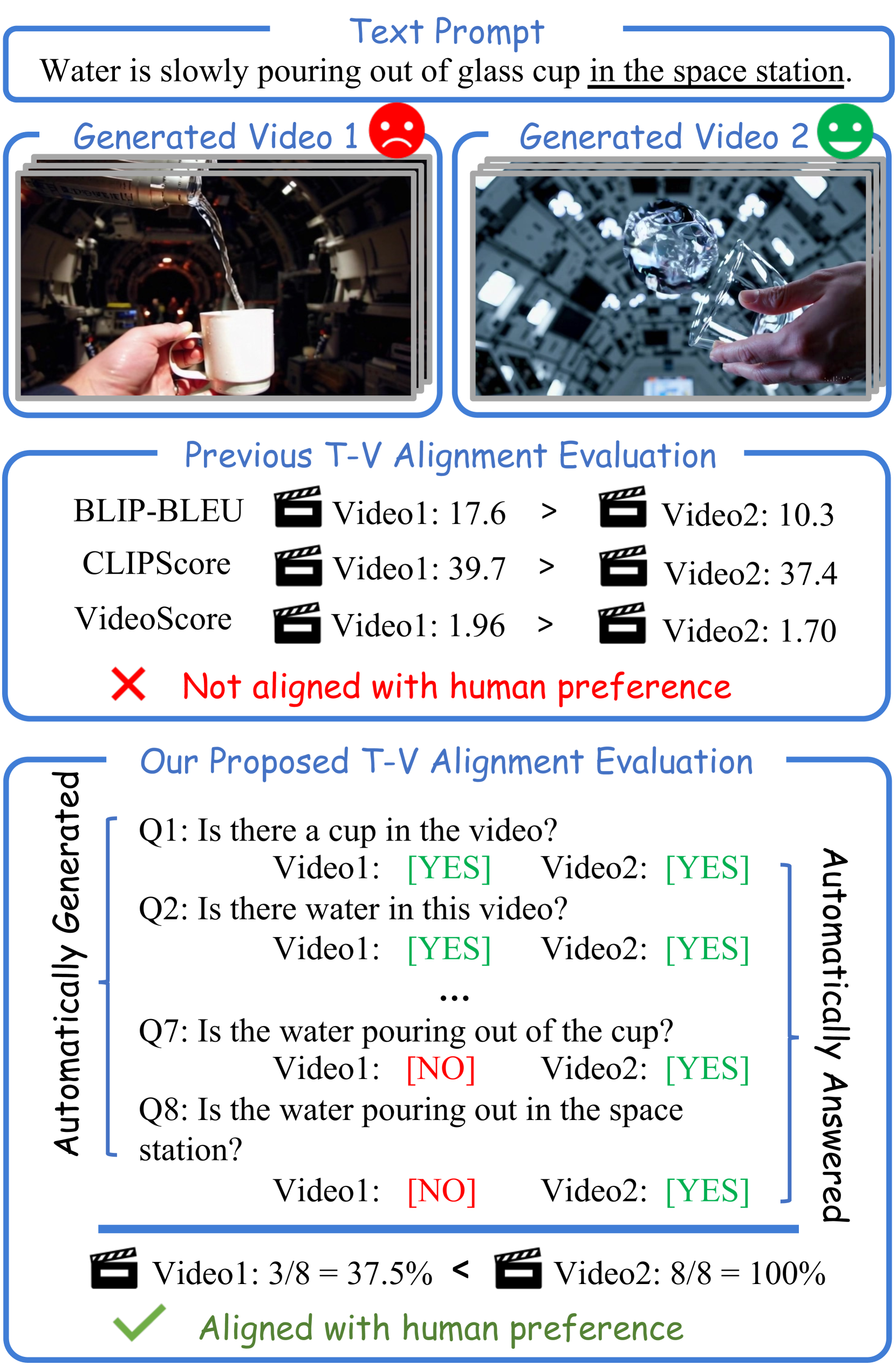
ETVA: Evaluation of Text-to-Video Alignment via Fine-grained Question ...
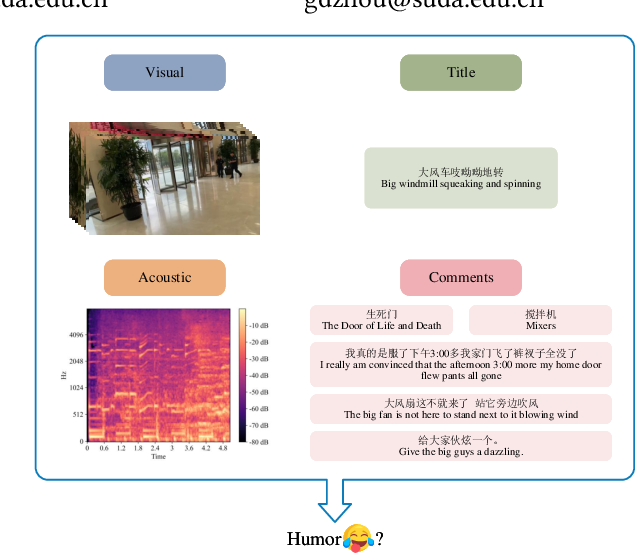
Figure 1 from Comment-aided Video-Language Alignment via Contrastive ...
Figure 1 from VideoCon: Robust Video-Language Alignment via Contrast ...
READ-PVLA: Recurrent Adapter with Partial Video-Language Alignment for ...
Paper page - VidLA: Video-Language Alignment at Scale
Figure 1 from VidLA: Video-Language Alignment at Scale | Semantic Scholar
PPT - Alignment Visualization PowerPoint Presentation, free download ...
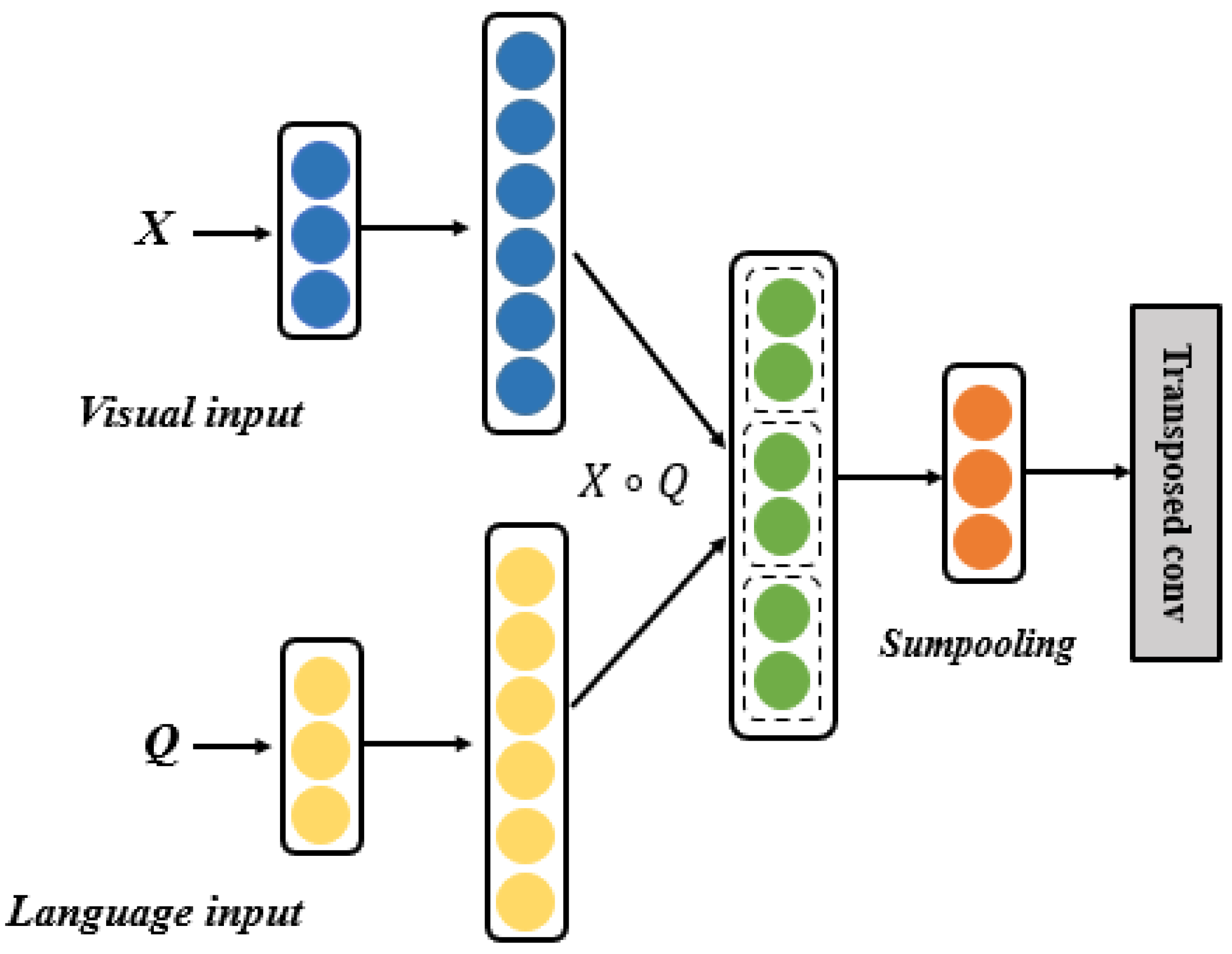
Video-Language alignment scores from R3M [24], InternVideo [41], and ...
Figure 1 from Clover: Towards A Unified Video-Language Alignment and ...
VidLA: Video-Language Alignment at Scale - 智源社区论文
Table 5 from Comment-aided Video-Language Alignment via Contrastive Pre ...
EP19 - VideoCon: Robust Video-Language Alignment via Contrast Captions ...
A Multi-level Alignment Training Scheme for Video-and-Language Grounding
Creating Video Subtitle Standards: Importance and Tips | GPI Blog
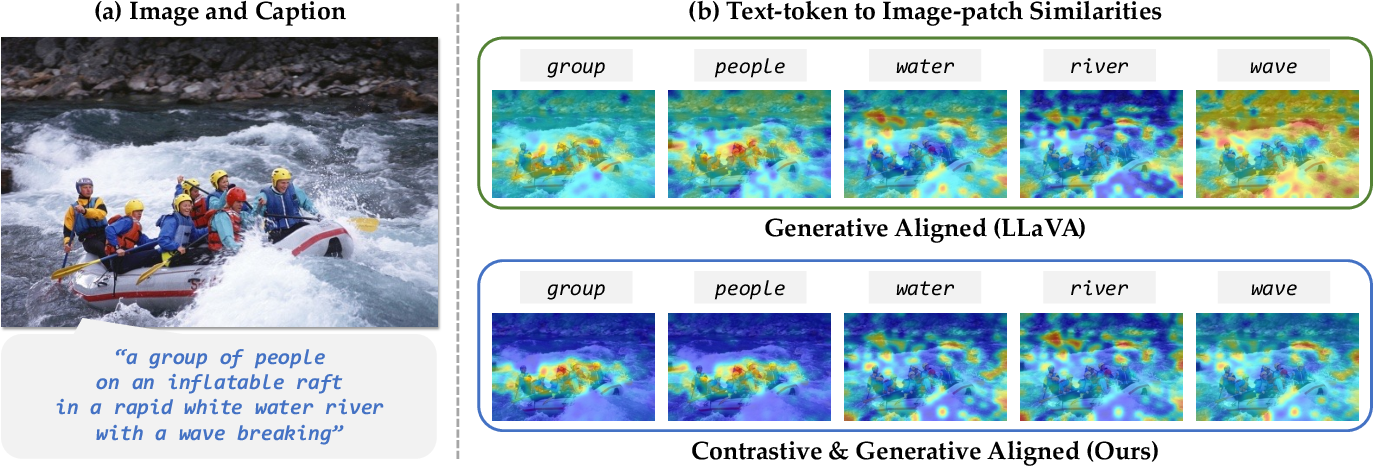
Figure 3 from Contrastive Vision-Language Alignment Makes Efficient ...
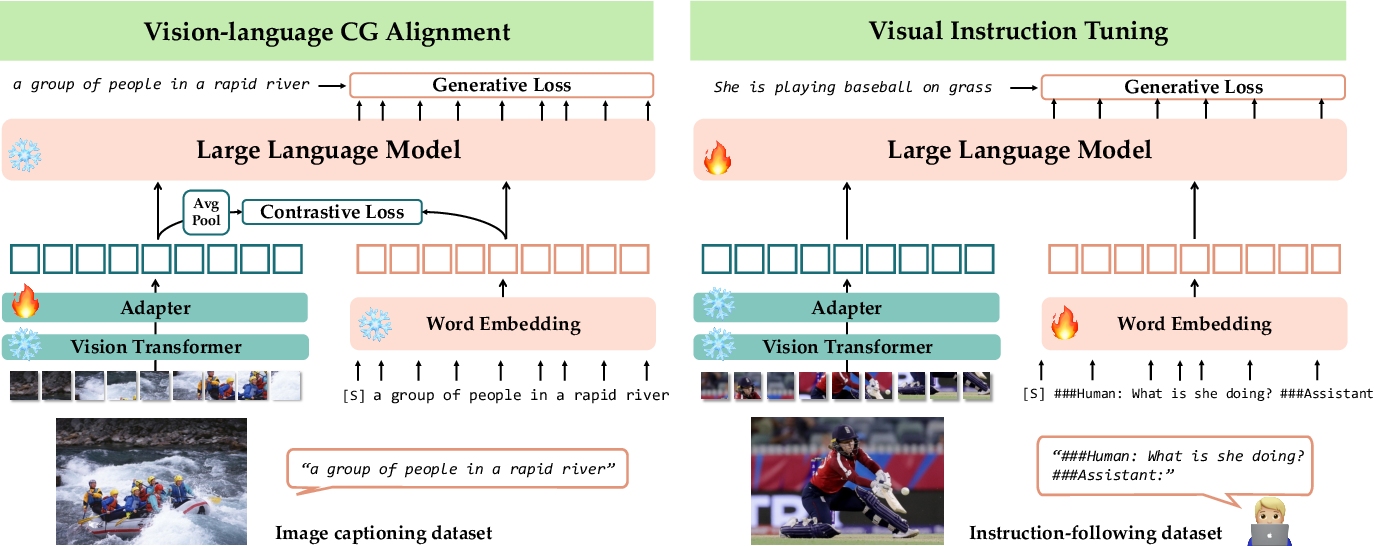
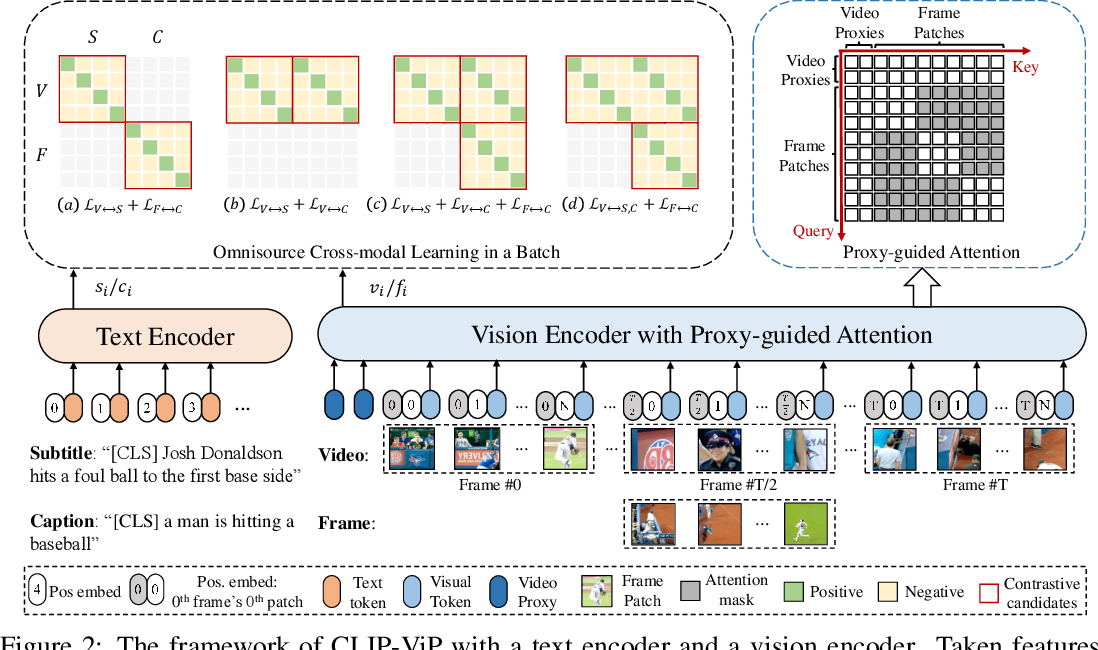
Figure 2 from CLIP-ViP: Adapting Pre-trained Image-Text Model to Video ...
A Strong Baseline for Temporal Video-Text Alignment
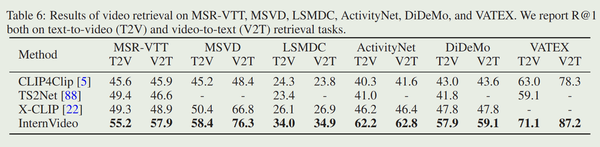
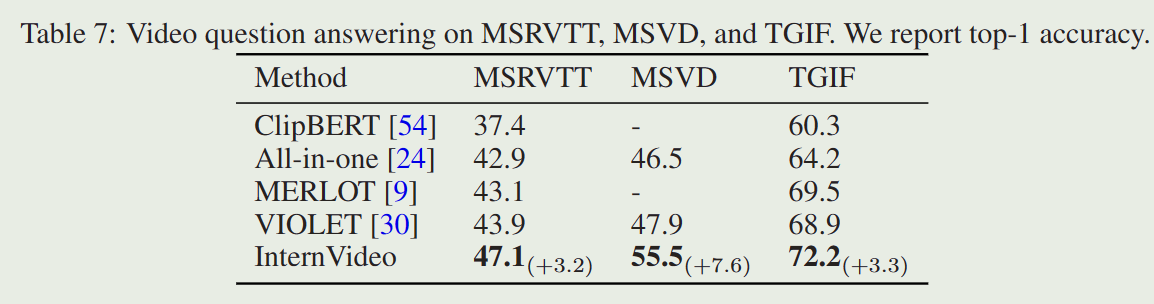
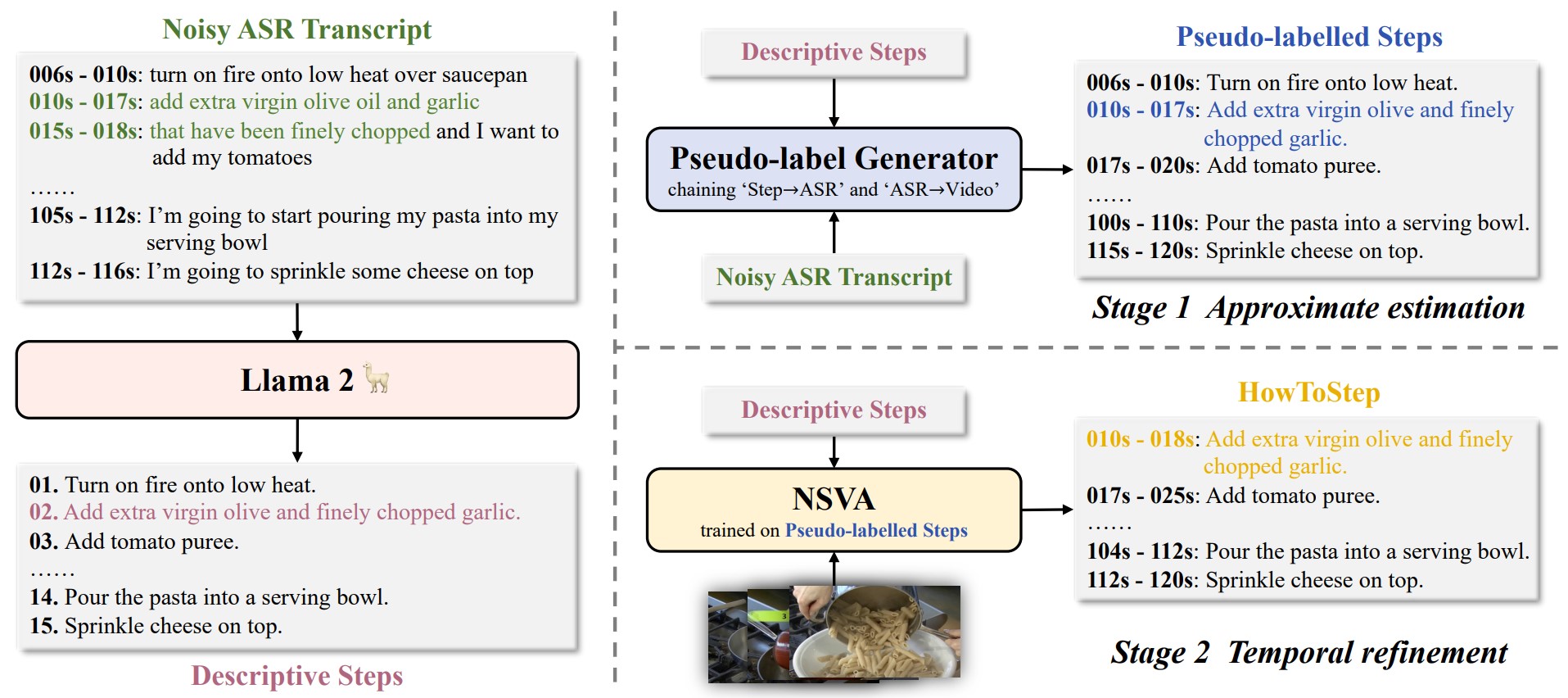
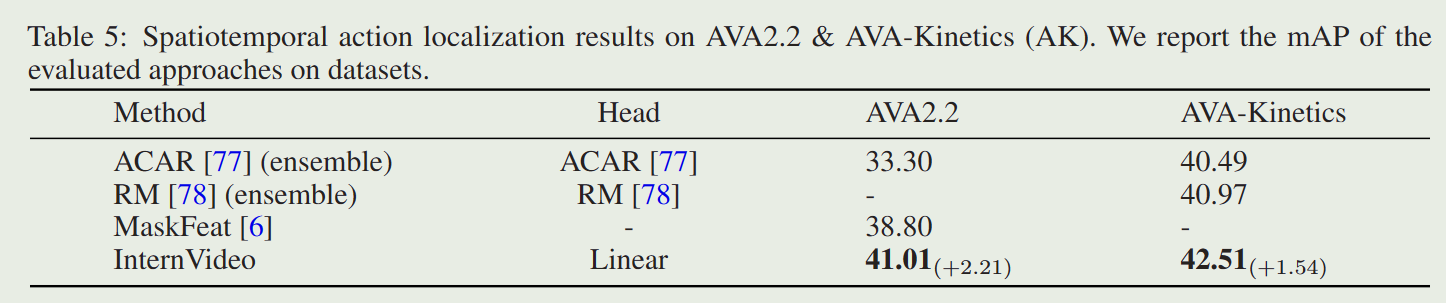
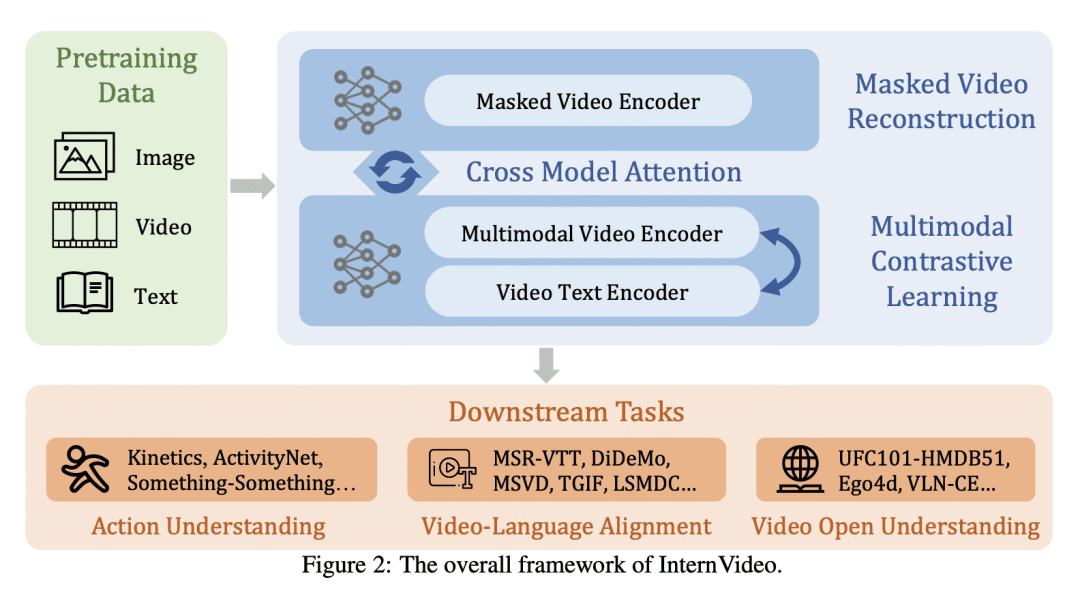
InternVideo: General Video Foundation Models via Generative and ...
Table 2 from CLIP-ViP: Adapting Pre-trained Image-Text Model to Video ...
Curriculum Learning for Data-Efficient Vision-Language Alignment | DeepAI
(a) Alignment between video, screenplay and closed captions; (b ...
[PDF] Aligning Source Visual and Target Language Domains for Unpaired ...
Multimodal Features Alignment for Vision–Language Object Tracking
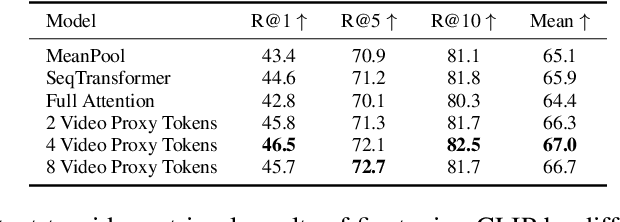
[2312.08367] VLAP: Efficient Video-Language Alignment via Frame ...
AI Summary: VLAP: Efficient Video-Language Alignment via Frame ...
Aligning Subtitles in Sign Language Videos | DeepAI
USC Media Communications Lab – MCL Research on Video-Text Alignment
Subspace Alignment for Vision-Language Model Test-time Adaptation | AI ...
【S2E10】Vision-and-Language Alignment - Towards Universal Multimodal AI ...
Can Linguistic Knowledge Improve Multimodal Alignment in Vision ...
Vision-Language Alignment | dvlab-research/LISA | DeepWiki
VL-SAE: Interpreting and Enhancing Vision-Language Alignment with a ...
Figure 2 from Contrastive Vision-Language Alignment Makes Efficient ...
Transforming Language Model Alignment: Zero-Shot Cross-Lingual Transfer ...
Supervision-free Vision-Language Alignment - YouTube
Paper page - LongAlign: A Recipe for Long Context Alignment of Large ...
(PDF) Language-Image Alignment with Fixed Text Encoders
Gestural Alignment in Spoken Simultaneous Interpreting: A Mixed-Methods ...
Towards Efficient Visual-Language Alignment of the Q-Former for Visual ...
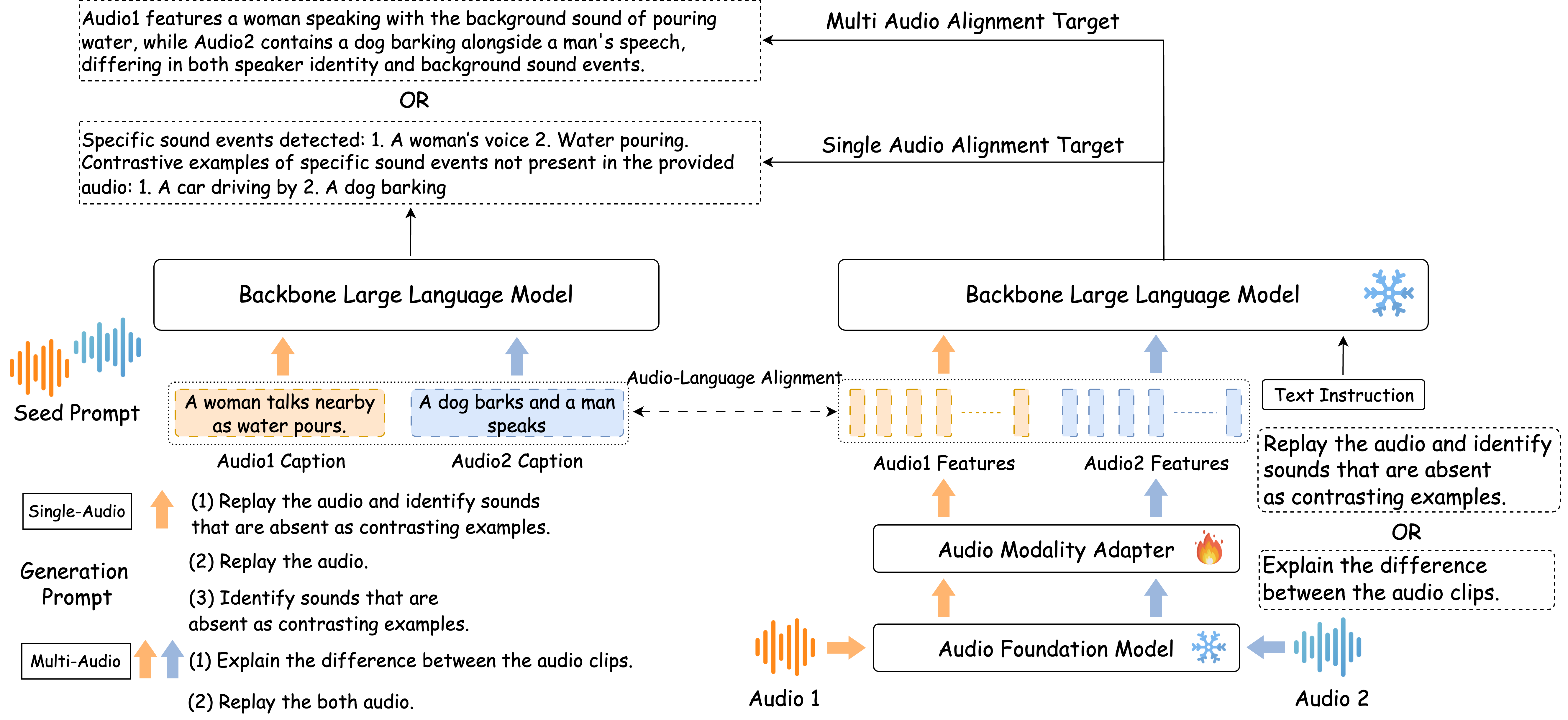
From Alignment to Advancement: Bootstrapping Audio-Language Alignment ...
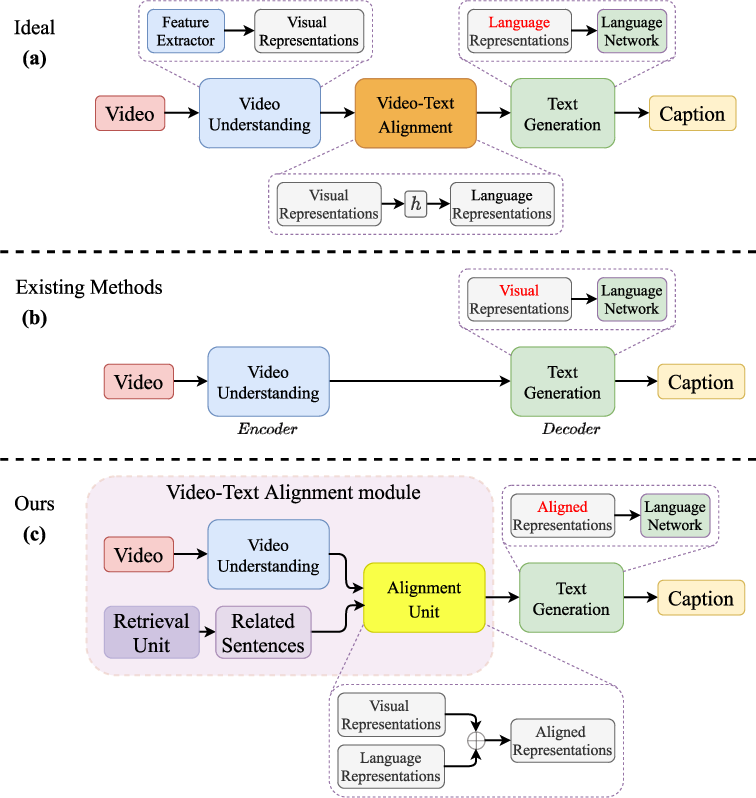
Re-Align: Aligning Vision Language Models via Retrieval-Augmented ...
Why is it important to Align Language Patterns when Leading Scaling ...
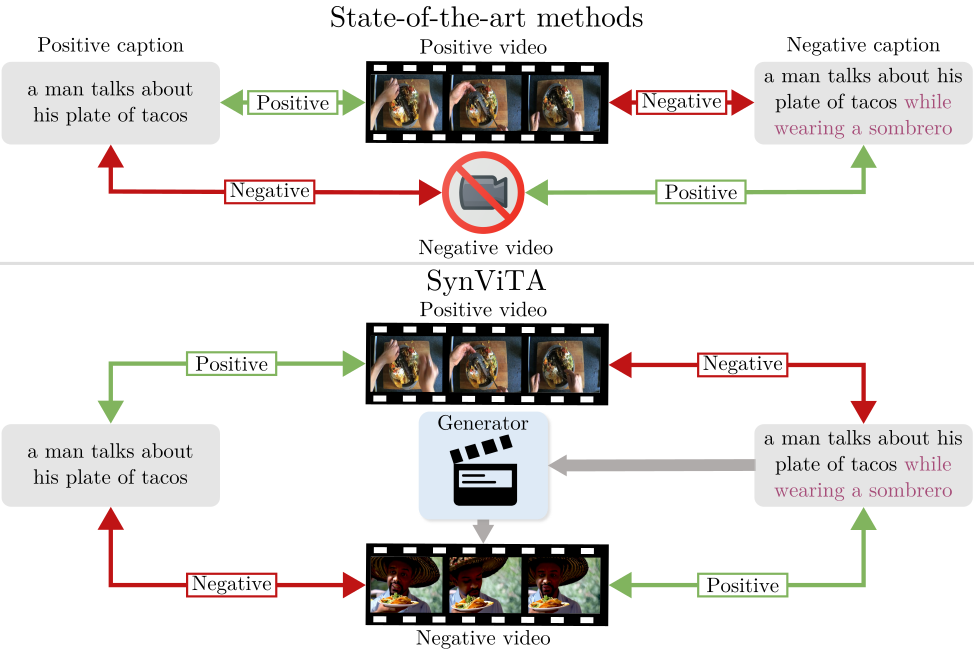
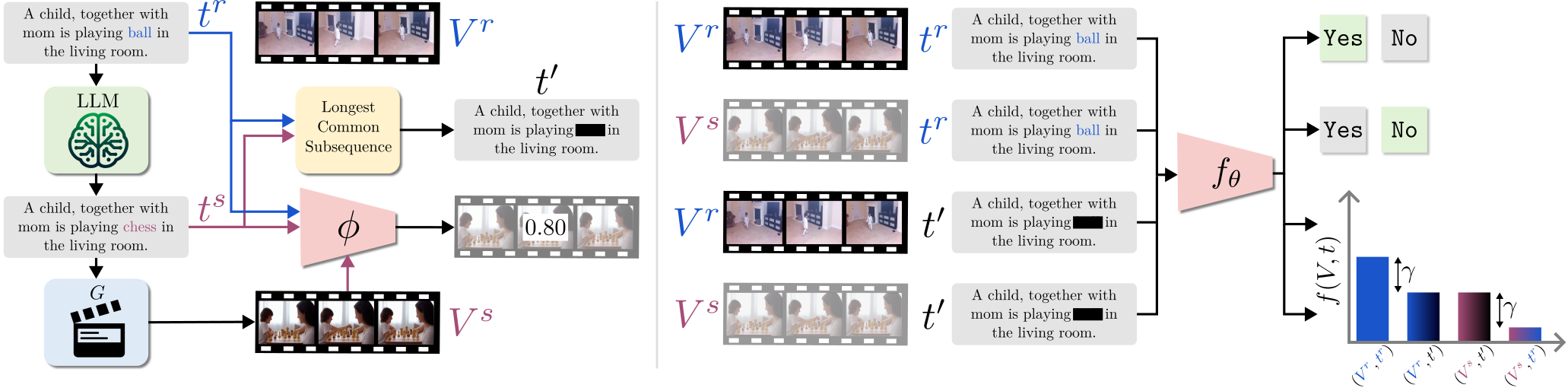
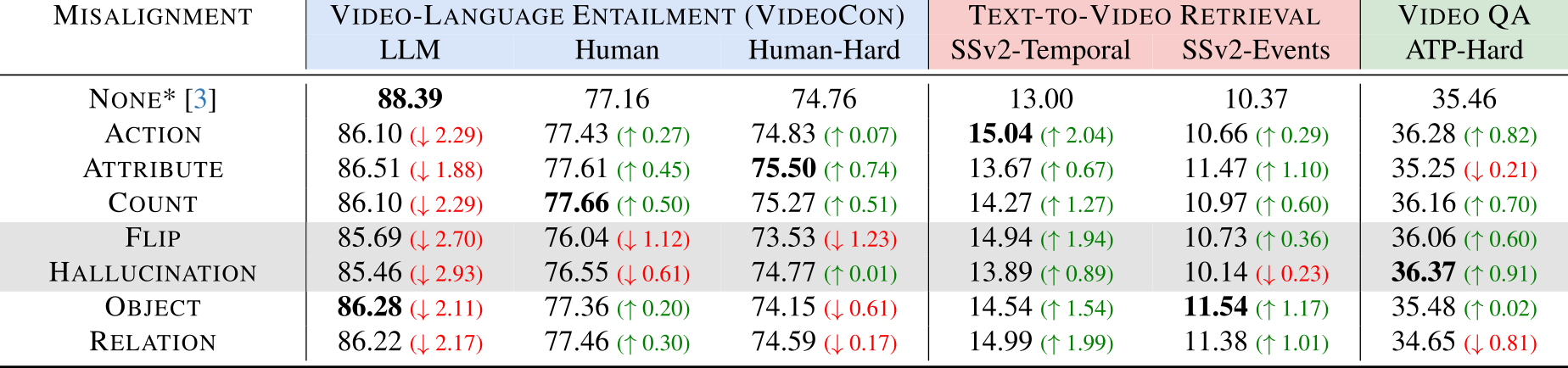
Can Text-to-Video Generation help Video-Language Alignment?
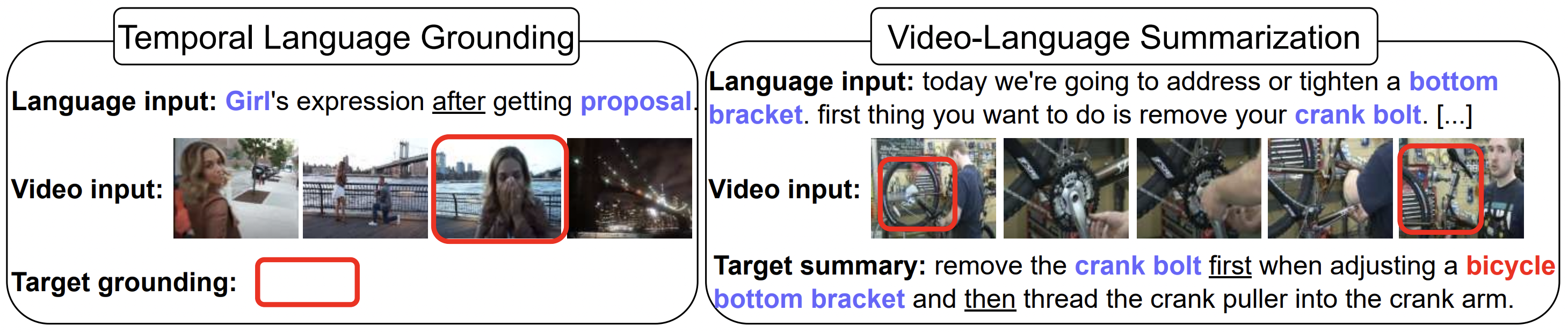
VideoCon
CVPR Poster Can Text-to-Video Generation help Video-Language Alignment?
READ
(PDF) Can Text-to-Video Generation help Video-Language Alignment?
(PDF) Graph-Based Video-Language Learning with Multi-Grained Audio ...
Learning Trajectory-Word Alignments for Video-Language Tasks | DeepAI
(PDF) Video+Language: From Classification to Description - DOKUMEN.TIPS
ALIGN: Scaling Up Visual and Vision-Language Representation Learning ...
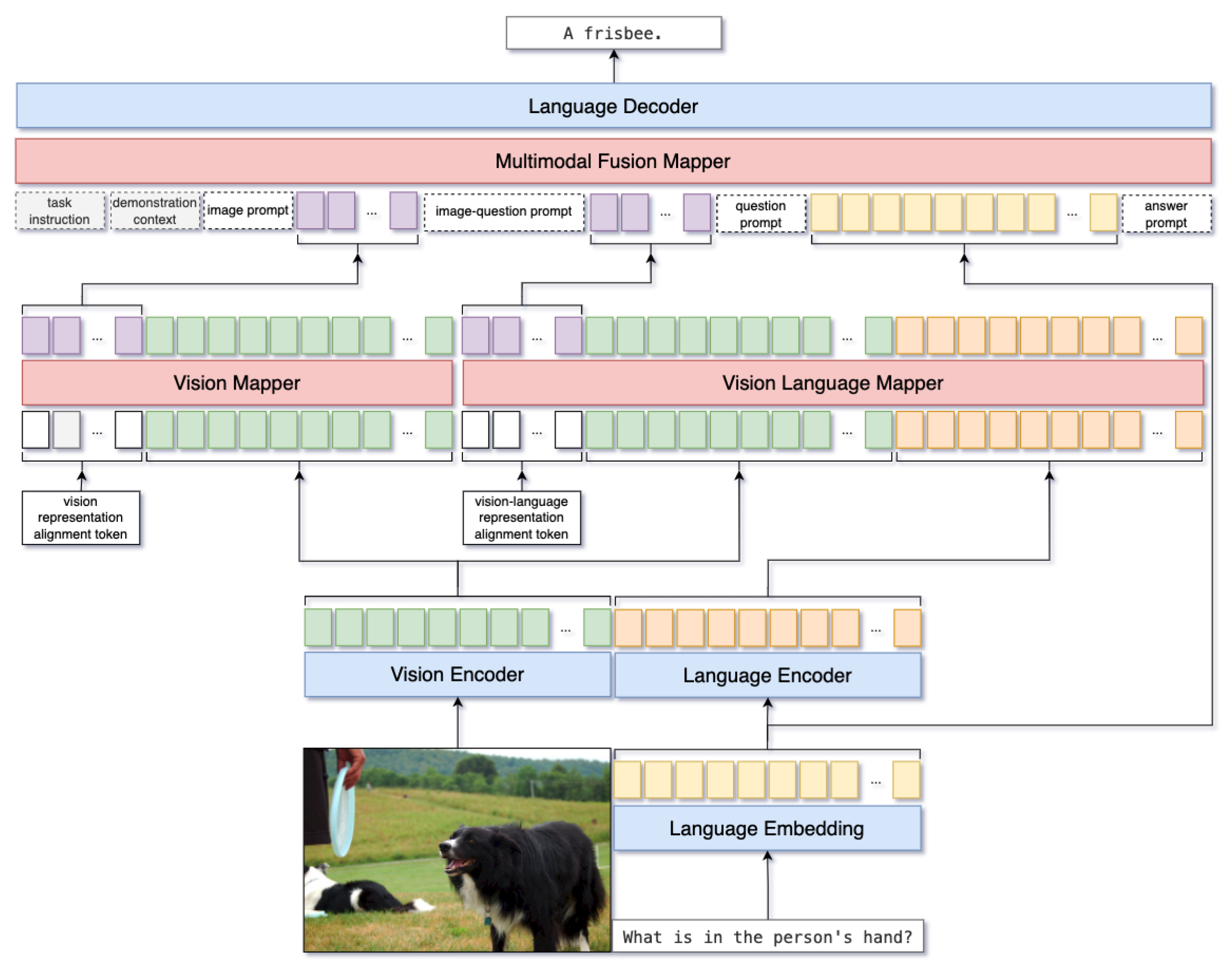
‘NExT-GPT’ – Video, Audio, Image, and Text – ‘Any-to-Any’ Multimodal ...
[2023.12.02]LMM近期进展 - 知乎
Figure 1 from Learning Trajectory-Word Alignments for Video-Language ...
SAIL
Microsoft Introduces Florence-VL: A Multimodal Model Redefining Vision ...
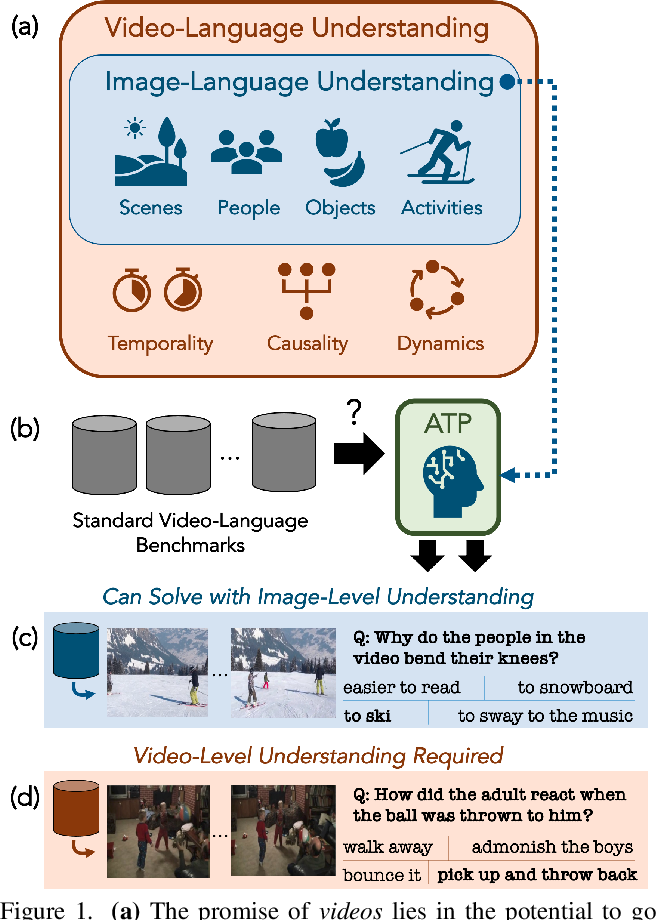
Figure 1 from Revisiting the “Video” in Video-Language Understanding ...
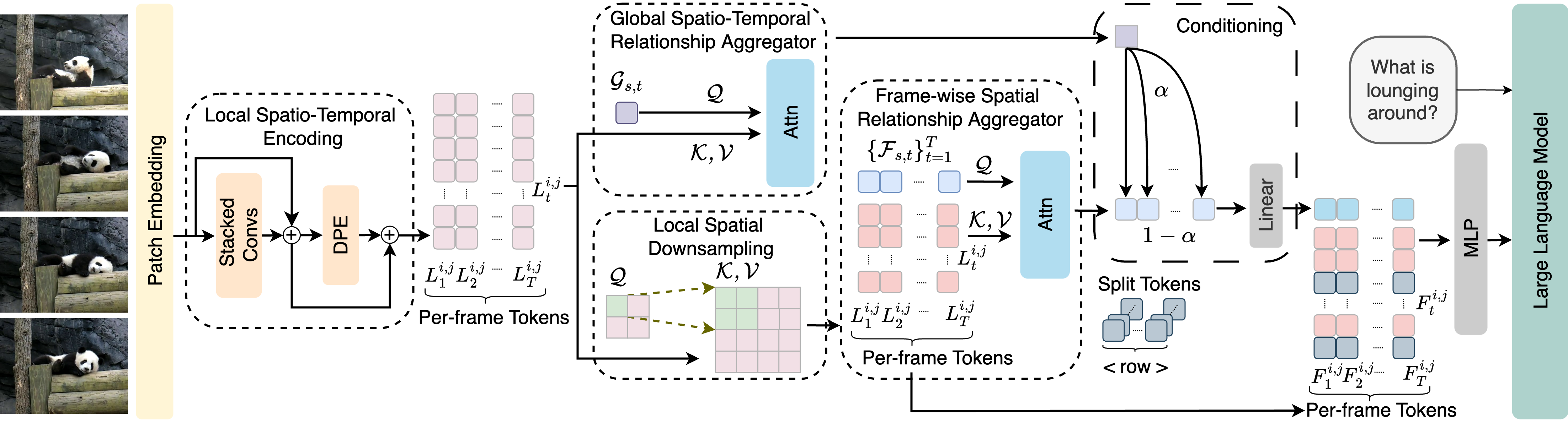
Enhancing Video-Language Representations with Structural Spatio ...
zhykoties/time-series-language-alignment · Datasets at Hugging Face
Introducing Video-To-Text and Pegasus-1 (80B)
基于生成式和鉴别式学习的通用视频基础模型 - 智源社区
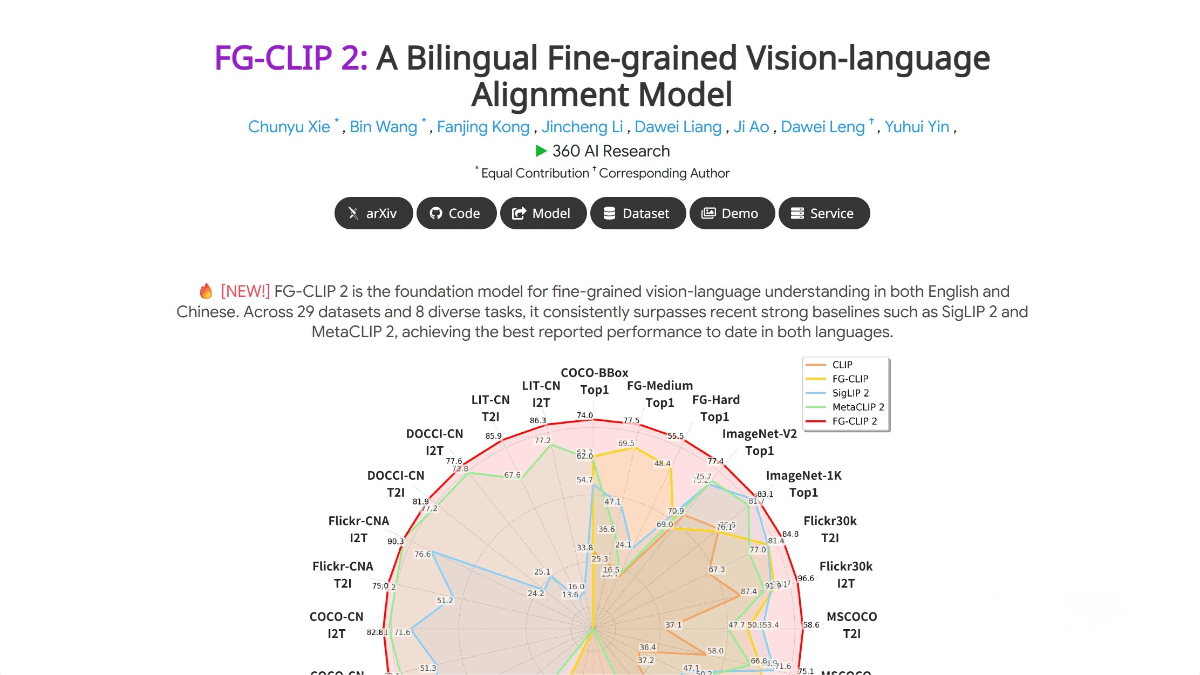
FG-CLIP 2 – 360 Open-Source Bilingual Fine-Grained Vision-Language ...